מהו קידוד טקסט?
קידוד טקסט (Text Encoding) הוא תהליך של המרת תווים לפורמט שניתן לאחסן ולשדר. סכימות קידוד שונות ממפות תווים לרצפי בייטים בדרכים שונות. בחירה בקידוד הנכון מבטיחה תאימות וייצוג טקסט נכון על פני פלטפורמות ויישומים שונים.
קידוד ASCII
קידוד ASCII (ראשי תיבות של American Standard Code for Information Interchange) הוא אחד מתקני קידוד התווים המוקדמים ביותר. הוא משתמש במספר בינארי של 7 סיביות כדי לייצג כל תו, ובכך מתאפשר ייצוג של 128 תווים ייחודיים.
מאפיינים:
- מייצג אותיות באנגלית, ספרות, סימני פיסוק ותווי בקרה.
- משתמש ב-7 ביטים לכל תו, עם ערכים הנעים בין 0 ל-127.
- פשוט ויעיל לטקסט באנגלית.
דוגמה:
A -> 65
B -> 66
a -> 97
b -> 98קידודי Unicode ו-UTF
Unicode הוא תקן קידוד תווים אוניברסלי שמטרתו לייצג את כל התווים מכל מערכות הכתיבה. קידודי Unicode כוללים UTF-8, UTF-16 ו-UTF-32.
קידוד UTF-8
UTF-8 הוא קידוד ברוחב משתנה המשתמש באחד עד ארבעה בייטים כדי לייצג כל תו. קידוד זה תואם לאחור עם ASCII ונמצא בשימוש נרחב באינטרנט.
מאפיינים:
- 1 בייט עבור תווי ASCII (0-127).
- 2 עד 4 בייטים עבור תווים אחרים.
- יעיל לטקסט עם תווי ASCII רבים.
דוגמה:
A -> 01000001 (1 byte)
€ -> 11100010 10000010 10101100 (3 bytes)קידוד UTF-16
UTF-16 הוא קידוד ברוחב משתנה המשתמש ביחידת קוד אחת או שתיים של 16 סיביות לייצוג תווים. הוא משמש לעתים קרובות בסביבות Windows ובשפות תכנות כמו Java ו-C#.
מאפיינים:
- 2 בייטים עבור תווים במישור הבסיסי הרב-לשוני (BMP) (U+0000 עד U+FFFF).
- 4 בייטים לתווים משלימים (U+10000 עד U+10FFFF).
דוגמה:
A -> 0041 (2 bytes)
𝄞 -> D834 DD1E (4 bytes)קידוד UTF-32
UTF-32 הוא קידוד ברוחב קבוע המשתמש בארבעה בייטים לכל תו.
בניגוד לקידודים UTF-8 ו-UTF-16 העושים שימוש ברוחב משתנה, קידוד UTF-32 הוא ברוחב קבוע. לכן, מצד אחד פשוט יותר לעבוד עם הקידוד הזה ומצד שני הוא מעט בזבזני יותר במקום.
מאפיינים:
- 4 בייטים לכל התווים.
- פשוט אבל משתמש ביותר זיכרון.
דוגמה:
A -> 00000041 (4 bytes)
€ -> 000020AC (4 bytes)קידודים נפוצים אחרים
ISO-8859-1 (לטינית-1)
ISO-8859-1 הוא קידוד של בייט בודד שיכול לייצג את 256 תווי Unicode הראשונים. הוא כולל תווים לשפות מערב אירופה.
דוגמה:
A -> 41
é -> E9Windows-1252
Windows-1252 הוא פיתוח (superset) של ISO-8859-1, וכולל תווים נוספים עבור סימני פיסוק וסמלים מסוימים.
דוגמה:
A -> 41
€ -> 80Windows-1255
Windows-1255 הוא קידוד של בייט בודד הכולל תווים לכתב עברי, דבר שהופך אותו למתאים לטקסט בשפה העברית.
דוגמה:
א -> E0
ב -> E1סימן סדר בייטים (BOM)
סימן סדר הבייטים (BOM) הוא תו מיוחד המשמש לציון סדר הבייטים (endianness) של קובץ טקסט או זרם טקסט (stream). הוא רלוונטי במיוחד עבור קידודי UTF-16 ו-UTF-32, אך יכול להופיע גם בקבצים בקידוד UTF-8. הבנת BOM חיונית להבטחת פרשנות ועיבוד טקסט נכונים במערכות וביישומים שונים.
מהו BOM?
סדר בייטים מתייחס לרצף שבו מאוחסנים או משודרים בייטים. ישנם שני סוגים של סדר בייטים:
- אנדיאן גדול Big Endian (BE) - הבייט המשמעותי ביותר ("הקצה הגדול") מאוחסן או משודר ראשון.
- אנדיאן קטן Small Endian (LE) - הבייט המשמעותי ביותר ("הקצה הקטן") מאוחסן או משודר ראשון.
לדוגמה, המספר 0x12345678 המאוחסן בסדר אנדיאן גדול יהיה 12 34 56 78, בעוד שבסדר אנדיאן קטן הוא יהיה 78 56 34 12.
מטרת השימוש ב-BOM
ה-BOM עוזר לזהות את הקידוד של קובץ הטקסט ואת סדר הבייטים בו נעשה שימוש. כאשר קובץ טקסט מתחיל עם BOM, הוא מסמן לקורא כיצד יש לפרש את הבייטים הבאים.
BOM בקידודים שונים:
- UTF-8 BOM
- EF BB BF
- UTF-16 BOM
- FE FF עבור Big Endian
- FF FE עבור Little Endian
- UTF-32 BOM
- 00 00 FE FF עבור Big Endian
- FF FE 00 00 עבור Little Endian
כאשר קיים BOM, הוא מציין את הקידוד המשמש עבור הטקסט. לדוגמה, EF BB BF בתחילת קובץ מסמל שהקובץ מקודד ב-UTF-8.
דוגמאות של BOM
ייצוג המחרוזת ABC ב-UTF-8 עם BOM:
EF BB BF 41 42 43
^ ^ ^ A B C
BOM "ABC"
ייצוג המחרוזת ABC ב-UTF-16 עם LE BOM:
FF FE 41 00 42 00 43 00
^ ^ A . B . C .
BOM "A" "B" "C"
ייצוג המחרוזת ABC ב-UTF-32 עם BE BOM:
00 00 FE FF 00 00 00 41 00 00 00 42 00 00 00 43
^ ^ ^ ^ . . . A . . . B . . . C
BOM "A" "B" "C"
טיפול ב-BOM בקוד
כאשר עובדים עם קובצי טקסט בקוד, ייתכן שיהיה עליך לטפל ב-BOM באופן מפורש, במיוחד בעת קריאה או כתיבה של קבצים בקידוד שונה.
דוגמה בג'אווה סקריפט:
// Reading a UTF-8 file with BOM
const fs = require('fs');
const data = fs.readFileSync('utf8_with_bom.txt', 'utf8');
// Check and remove BOM if present
if (data.charCodeAt(0) === 0xFEFF) {
data = data.slice(1);
}
console.log(data);דוגמה ב-PHP:
// Reading a UTF-8 file with BOM
$data = file_get_contents('utf8_with_bom.txt');
// Check and remove BOM if present
if (substr($data, 0, 3) === "\xEF\xBB\xBF") {
$data = substr($data, 3);
}
echo $data;בעיות נפוצות עם קידודים
השחתת תווים
השחתה של התווים מתרחשת כאשר טקסט המקודד בפורמט אחד מתפרש באופן שגוי כקידוד אחר. לעתים קרובות הדבר גורם לתווים משובשים או שגויים, דבר שמכונה בשפה העממית ג'יבריש.
אובדן נתונים
אובדן נתונים יכול לקרות בעת המרה בין קידודים שאינם תומכים באותה ערכת תווים. ניתן להחליף תווים שלא ניתן לייצוג בקידוד היעד במציין מיקום או להשמיט אותם.
תאימות בין פלטפורמות
מערכות ויישומים שונים עשויים להשתמש בקידודי ברירת מחדל שונים. הדבר מוביל לבעיות תאימות בעת שיתוף נתוני טקסט. הבטחת השימוש בקידוד נפוץ, לדוגמה UTF-8, יכולה להפחית את הבעיות הללו.
בחירת הקידוד הנכון
בחירת הקידוד הנכון תלויה בדרישות האפליקציה שלך:
- UTF-8 - הטוב ביותר עבור יישומי אינטרנט וטקסט עם תווי ASCII רבים. תמיכה רחבה ויעיל.
- UTF-16 - מתאים ליישומים הדורשים שימוש נרחב בתווים שאינם לטיניים, כמו סקריפטים אסייתיים מסוימים.
- UTF-32 - אידיאלי כאשר הפשטות קריטית יותר משימוש בזיכרון, כגון בתרחישי עיבוד פנימיים מסוימים.
- ISO-8859-1 ו-Windows-1252 - שימושי עבור מערכות מדור קודם ויישומים אזוריים מסוימים.
דוגמאות וטיפים מעשיים
דוגמה 1: קריאה וכתיבה של קבצי UTF-8 ב-Python
# Writing to a UTF-8 file
with open('example.txt', 'w', encoding='utf-8') as f:
f.write('Hello, world! €')
# Reading from a UTF-8 file
with open('example.txt', 'r', encoding='utf-8') as f:
content = f.read()
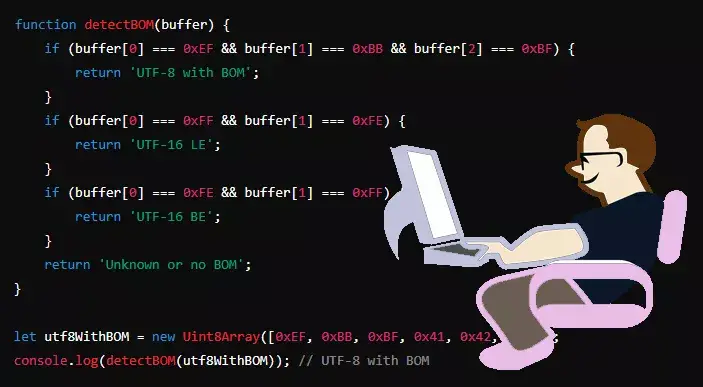
print(content)דוגמה 2: זיהוי BOM ב-JavaScript
function detectBOM(buffer) {
if (buffer[0] === 0xEF && buffer[1] === 0xBB && buffer[2] === 0xBF) {
return 'UTF-8 with BOM';
}
if (buffer[0] === 0xFF && buffer[1] === 0xFE) {
return 'UTF-16 LE';
}
if (buffer[0] === 0xFE && buffer[1] === 0xFF) {
return 'UTF-16 BE';
}
return 'Unknown or no BOM';
}
let utf8WithBOM = new Uint8Array([0xEF, 0xBB, 0xBF, 0x41, 0x42, 0x43]);
console.log(detectBOM(utf8WithBOM)); // UTF-8 with BOMמסקנה
הבנת קידוד טקסט חיונית למפתחים העובדים עם שפות ופלטפורמות מגוונות. ASCII, UTF-8, UTF-16 וקידודים אחרים, לכל אחד מהם יש את החוזקות ואת מקרי השימוש שלו. ה-BOM ממלא תפקיד מכריע בציון סדר בייטים עבור קידודים מסוימים.
על ידי בחירת הקידוד המתאים, מודעות ל-BOM והבנת בעיות נפוצות, ניתן להבטיח שנתוני הטקסט מיוצגים ומפורשים בצורה נכונה על פני מערכות ויישומים שונים.
סרטון מומלץ להעשרה בנושא: